Apache Beam2.3.4(Python)で導入されたwith_exception_handlingを使ってみる
ZOZO Advent Calendar 2021 5日目の記事です。
Apache Beam2.34.0(Python)のバージョンにおいてwith_exception_handling機能が追加されたので紹介します。
with_exception_handlingについて
Apache Beamを利用しPipelineを作成する際、何かしらの条件で処理を分岐したい場合があると思います。その際はTaggedOutput を利用し処理を分岐できます。利用方法に関しては下記にまとまっています。
今回紹介するwith_exception_handling機能ではTaggedOutputのようにoutput先を変更できます。TaggedOutputとは違い、明示的にoutput先を指定せずとも例外が投げられた場合に条件を分岐できます。実装が気になる方やどのようなオプションが利用できるかについては下記をご覧ください。
実装
今回はwith_exception_handling機能を利用しCloud Pub/SubからBigQueryのテーブルへinsertする処理を実装してみます。具体的なフローは下記になります。

Apache Beam内で例外が発生しなかった場合はsampleテーブルへinsertを行います。例外が発生した場合はsample_error_recordテーブルへinsertするような処理になります。
開発環境
今回利用したライブラリや言語のバージョンは下記になります。
テーブル定義
以下2つのテーブルを利用します。カラム名は適当です。
sample
| Column | Type | Option |
|---|---|---|
| description | string | NULLABLE |
sample_error_record
| Column | Type | Option |
|---|---|---|
| description | string | NULLABLE |
| error_message | string | NULLABLE |
実装
実装したPythonコードは下記になります。subscription_id等一部パラメーターは適当に置き換えてます。
import apache_beam as beam import json class Sample(beam.DoFn): def process(self, message): if message["description"] == "error": raise Exception("Test Error") yield message def format_error_message(error_messages): error_message = (''.join(map(str, error_messages[1]))) message = error_messages[0] message["error_message"] = error_message return message class TestPipeline(beam.DoFn): def pipeline(self): subscription_id="subscription_id" table_id = "table_id" options = beam.options.pipeline_options.PipelineOptions() with beam.Pipeline(options=options) as p: message, error_message = ( p | "Read message from Cloud Pub/Sub" >> beam.io.gcp.pubsub.ReadFromPubSub(subscription=subscription_id) | 'convert json' >> beam.Map(json.loads) | "Something" >> beam.ParDo(Sample()).with_exception_handling() ) ( error_message | 'Format error message' >> beam.Map(format_error_message) | 'Write to deadletter table' >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id + "_error_record" ) ) ( message | 'Write to table' >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id ) ) def run(): test = TestPipeline() test.pipeline() if __name__ == '__main__': run()
ParDoで利用するSampleクラス内の処理で意図的に例外を発生してwith_exception_handling()の振る舞いを確認します。
結果
以下のようなjsonが送られた場合は正常のテーブルへinsertします。
{ "description": "test" }
このjsonメッセージの結果は下記になります。
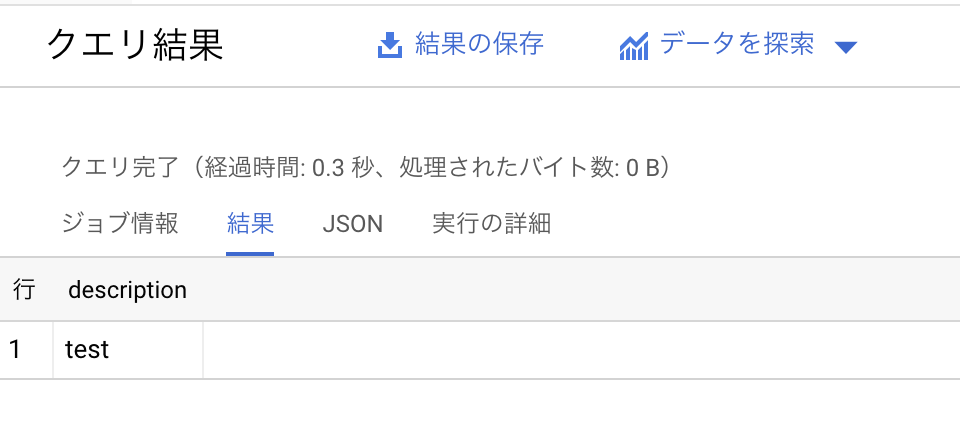
sampleテーブルへinsertされたことが確認できました。
次に、以下のようなjsonが送られた場合はエラーテーブルへinsertします。
{ "description": "error" }
このjsonメッセージの結果は下記になります。

sample_error_recordテーブルへinsertされたことが確認できました。
まとめ
with_exception_handlingを利用し、例外発生の有無によりPipelineの処理を分岐できました。以前は例外が発生した場合はその例外をキャッチし、都度TaggedOutputを利用し別処理を行う必要がありました。しかしwith_exception_handlingの利用でキャッチをせずとも別処理へ分岐可能になりました。TaggedOutputとwith_exception_handlingを使い分けることでより分岐の処理が書きやすくなったと思うのでぜひ利用してみてください。