ZOZO Advent Calendar 2021 22日目の記事です。
今回はDataflow内に送られてくるログサイズの制限を行う実装をします。
経緯
下記の構成図のようにCloud Pub/Subに送られてくるログをBigQueryにinsertするような処理をDataflowを用いて実装します。加えて、DataflowのStreaming機能を利用しリアルタイムでログをBigQueryへinsertします。

しかし、上記の構成でログをinsertする際BigQueryのquotas/limitsに引っかかる場合があります。 BigQueryのquotas/limitsは下記に記載されています。今回はStreaming機能を有効にしているのでStreaming insertsのquotas/limitsが適用されます。

特に今回はHTTP request size limitの項目に注目します。HTTP request size limitはstreaming insertのAPI(insertAll)へ一度に投げられるサイズ制限になります。制限量に関しては10MBあるので1ログメッセージ程度では制限に引っかかることはありません。しかしinsertAllは複数のinsertデータを含めることができます。
Dataflow側は複数insertできることを利用し、ある程度ログメッセージをまとめてinsertします。どれくらいまとめてinsertを行うかはDataflow側が決めており、流れてくるログ量によって変化します。なので、データのサイズが大きいログが短時間で大量に送られてくるとBigQueryの10MBのログ制限に引っかかってしまう場合があります。Dataflow側ではログのサイズを加味してinsertする量を調節しないので意図的にログサイズの確認を行い、大きいサイズのログが送られた場合は棄却する、切り詰める等の処理を行う必要があります。大きいサイズのログをどう処理するかに関しては要件によると思うのですが、今回はログサイズの切り詰めを行い、Deadletterテーブルへ書き込むような処理を紹介します。
検証環境
以下のバージョンで実装を行います。
Python 3.8.11
apache-beam 2.34.0
実装手順
以下の図のような実装を行います。
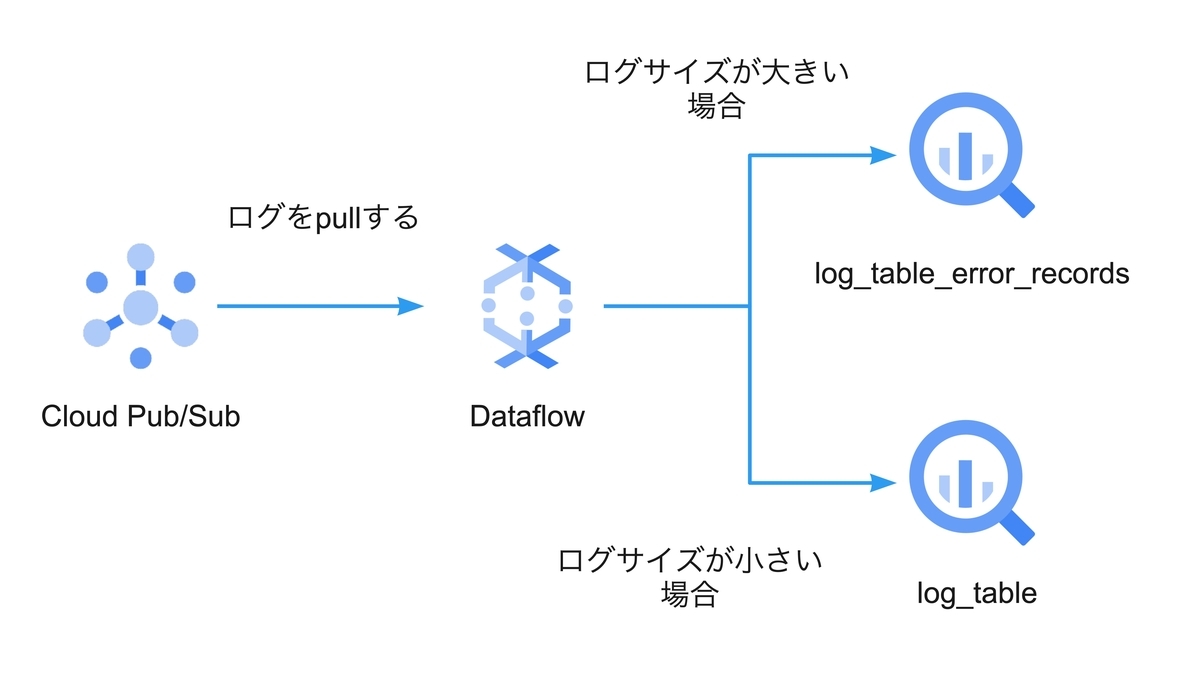
Dataflow内でCloud Pub/Subから送られてきたログに対してサイズの確認を行います。ログのサイズが規定のサイズより大きかった場合はdeadletterテーブル(log_table_error_records)へ、小さかった場合は正常のテーブル(log_table)へinsertします。
実装
具体的な実装は下記になります。
import os import math import apache_beam as beam class ValidateLogSizeAndResizeLogSize(beam.DoFn): def __init__(self, max_log_kilobyte_size): self.max_log_kilobyte_size = max_log_kilobyte_size self.log_kilobyte_size = 0 def _caluclate_log_size(self, log): serialized_log = json.dumps(log) log_byte_size = len(serialized_log.encode()) log_kilobyte_size = math.floor(log_byte_size/1024) return log_kilobyte_size def _check_max_log_size_exceeded(self): return True if self.log_kilobyte_size > self.max_log_kilobyte_size else False def _resize_log_size(self, log): serialized_log = json.dumps(log) encoded_log = serialized_log.encode() return encoded_log[:self.max_log_kilobyte_size*1024].decode(errors='ignore') def process(self, log): self.log_kilobyte_size = self._caluclate_log_size(log) if self._check_max_log_size_exceeded(): resized_log = self._resize_log_size(log) message = f"Event log size too large. Expected Max size is {self.max_log_kilobyte_size}kb. But recived {self.log_kilobyte_size}kb event log" yield beam.pvalue.TaggedOutput("failed_max_size", {"log": resized_log, "error_message": message}) return else: yield log def format_error_log(payload): return {'payloadString': json.dumps(payload["log"]), 'errorMessage': payload["error_message"],'timestamp': datetime.now(timezone.utc).strftime("%Y-%m-%dT%H:%M:%S.%fZ")} class CustomOptions(PipelineOptions): @classmethod def _add_argparse_args(cls, parser): parser.add_argument('--batch_size', default=None, type=int, required=True) parser.add_argument('--max_log_kilobyte_size', default=None, type=int, required=True) class TestPipeline(beam.DoFn): def __init__(self, argment): self.argment = CustomOptions() def pipeline(self): subscription_id="subscription_id" table_id = "table_id" with beam.Pipeline(options=self.argment) as p: checked_logs_size = ( p | f"Read message from Cloud Pub/Sub" >> beam.io.gcp.pubsub.ReadFromPubSub(subscription=platform.pubsub_subsciption_id()) | f"Convert json" >> beam.Map(json.loads) | f"Validate max logs size" >> beam.ParDo(ValidateLogSizeAndResizeLogSize(p._options.max_log_kilobyte_size)).with_outputs('failed_max_size', main='vailed_max_size') ) ( checked_logs_size.failed_max_size | f'Format error log' >> beam.Map(format_error_log) | f'Write to deadletter table' >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id + "_error_record", batch_size=p._options.batch_size ) ) ( checked_logs_size.vailed_max_size | f"Write to BigQuery table" >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id, batch_size=p._options.batch_size ) ) def run(): test = TestPipeline() test.pipeline() if __name__ == '__main__': run()
deadletterテーブルへのinsert及び正常テーブルのinsertはwith_outputsを利用しinsertするテーブルを変更しています。
BigQueryのinisertを行う関数はWriteToBigQuery関数です。引数にbatch_sizeを指定でき、一度にinsertできるmaxのレコード数を設定できます。デフォルトだと500が指定されており、場合によってはBigQueryのHTTP request size limitに引っかかる可能性があるのでオプションで任意の値に変更できるようにしています。
ログサイズの確認、リサイズを行う関数はValidateLogSizeAndResizeLogSize関数です。Dataflow起動時にオプションでログサイズの閾値を渡せるようにし、その閾値を用いて送られてくるログに対して比較を行います。
まとめ
送られてくるログに対してログサイズの制限を設けられました。送られてくるログサイズが小さい場合はBigQueryのquotas/limitsに引っかかることはないのですが、batch_sizeの設定やログサイズが大きい場合は何かしらの制限を設ける処理を追加することをおすすめします。閾値設定は毎秒どれくらいメッセージが送られてくるのかだったり、どれくらいのログサイズだったかで適宜変更する必要があるので、その際はこの記事の実装を参考にしていただければと思います。