Apache Beam2.3.4(Python)で導入されたwith_exception_handlingを使ってみる
ZOZO Advent Calendar 2021 5日目の記事です。
Apache Beam2.34.0(Python)のバージョンにおいてwith_exception_handling機能が追加されたので紹介します。
with_exception_handlingについて
Apache Beamを利用しPipelineを作成する際、何かしらの条件で処理を分岐したい場合があると思います。その際はTaggedOutput を利用し処理を分岐できます。利用方法に関しては下記にまとまっています。
今回紹介するwith_exception_handling機能ではTaggedOutputのようにoutput先を変更できます。TaggedOutputとは違い、明示的にoutput先を指定せずとも例外が投げられた場合に条件を分岐できます。実装が気になる方やどのようなオプションが利用できるかについては下記をご覧ください。
実装
今回はwith_exception_handling機能を利用しCloud Pub/SubからBigQueryのテーブルへinsertする処理を実装してみます。具体的なフローは下記になります。

Apache Beam内で例外が発生しなかった場合はsampleテーブルへinsertを行います。例外が発生した場合はsample_error_recordテーブルへinsertするような処理になります。
開発環境
今回利用したライブラリや言語のバージョンは下記になります。
テーブル定義
以下2つのテーブルを利用します。カラム名は適当です。
sample
| Column | Type | Option |
|---|---|---|
| description | string | NULLABLE |
sample_error_record
| Column | Type | Option |
|---|---|---|
| description | string | NULLABLE |
| error_message | string | NULLABLE |
実装
実装したPythonコードは下記になります。subscription_id等一部パラメーターは適当に置き換えてます。
import apache_beam as beam import json class Sample(beam.DoFn): def process(self, message): if message["description"] == "error": raise Exception("Test Error") yield message def format_error_message(error_messages): error_message = (''.join(map(str, error_messages[1]))) message = error_messages[0] message["error_message"] = error_message return message class TestPipeline(beam.DoFn): def pipeline(self): subscription_id="subscription_id" table_id = "table_id" options = beam.options.pipeline_options.PipelineOptions() with beam.Pipeline(options=options) as p: message, error_message = ( p | "Read message from Cloud Pub/Sub" >> beam.io.gcp.pubsub.ReadFromPubSub(subscription=subscription_id) | 'convert json' >> beam.Map(json.loads) | "Something" >> beam.ParDo(Sample()).with_exception_handling() ) ( error_message | 'Format error message' >> beam.Map(format_error_message) | 'Write to deadletter table' >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id + "_error_record" ) ) ( message | 'Write to table' >> beam.io.gcp.bigquery.WriteToBigQuery( table=table_id ) ) def run(): test = TestPipeline() test.pipeline() if __name__ == '__main__': run()
ParDoで利用するSampleクラス内の処理で意図的に例外を発生してwith_exception_handling()の振る舞いを確認します。
結果
以下のようなjsonが送られた場合は正常のテーブルへinsertします。
{ "description": "test" }
このjsonメッセージの結果は下記になります。
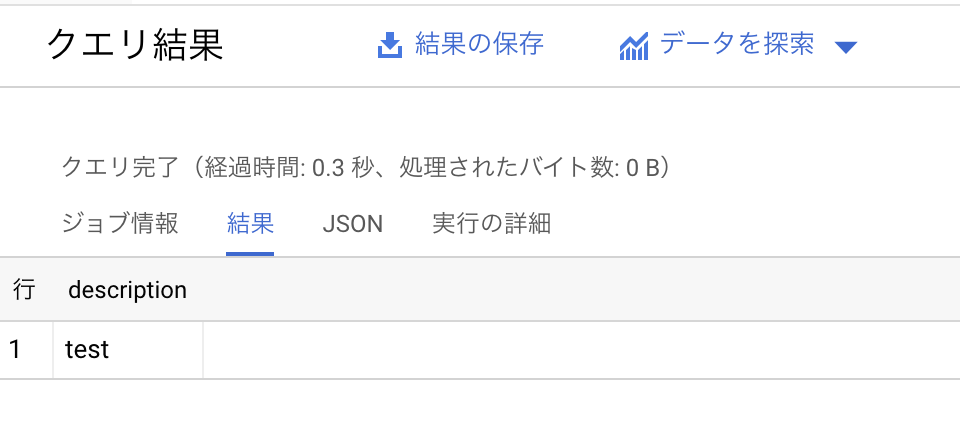
sampleテーブルへinsertされたことが確認できました。
次に、以下のようなjsonが送られた場合はエラーテーブルへinsertします。
{ "description": "error" }
このjsonメッセージの結果は下記になります。

sample_error_recordテーブルへinsertされたことが確認できました。
まとめ
with_exception_handlingを利用し、例外発生の有無によりPipelineの処理を分岐できました。以前は例外が発生した場合はその例外をキャッチし、都度TaggedOutputを利用し別処理を行う必要がありました。しかしwith_exception_handlingの利用でキャッチをせずとも別処理へ分岐可能になりました。TaggedOutputとwith_exception_handlingを使い分けることでより分岐の処理が書きやすくなったと思うのでぜひ利用してみてください。
Scrapyのキャッシュを定期的に削除する
ZOZOテクノロジーズ #1 Advent Calendar 2020 23日目です。 ScrapyのCacheにおいて定期的にCacheを削除するような機能を作成したので紹介します。
ScrapyのCacheについて
ScrapyのCacheはHttpCacheMiddlewareで実装されています。
Cacheを有効にするとScrapyからリクエストを送った後に返ってきたレスポンスをCacheし、再度同じリクエストを送った際にCacheのデータを利用することができます。
Cacheを利用することによってクローリング対象のサーバへのリクエストを減らすことができます。
またCacheを保存する場所においてはデフォルトでlocalに保存されます。保存場所は変更可能で、DBや他のミドルウェアに設定可能です。
今回はデフォルトのlocalに保存される場合の話になります。
HTTPCACHE_EXPIRATION_SECSについて
Scrapy側でCacheを削除できる機能が存在するのか調査を行いました。
Scrapyが提供しているCache関連で設定できる環境変数を調べるとHTTPCACHE_EXPIRATION_SECSが設定できます。
HTTPCACHE_EXPIRATION_SECSはCacheに有効期限を設定できる設定になります。自分は最初HTTPCACHE_EXPIRATION_SECSを設定すればCacheを削除されると思ってました。しかし実装を追ってみると、特に削除されないことがわかりました。
実際にどのように実装されているのか中身を見てみようと思います。
HttpCacheMiddlewareの実装場所はhttpcache.pyになります。
storageの選択に関してはinit部分のstorageの部分で設定されます。デフォルトではscrapy.extensions.httpcache.FilesystemCacheStorageが設定されています。
self.storage = load_object(settings['HTTPCACHE_STORAGE'])(settings)
よってextensionsに配置されているFilesystemCacheStorageクラスがhttpcache.pyで利用されるようになります。
Cacheを利用する際はretrieve_responseメソッドが呼び出されます。メソッド内の_read_meta部分で 有効期限の条件分岐が実装されています。
実装箇所を確認すると下記のように実装されています。
if 0 < self.expiration_secs < time() - mtime: return # expired
実装より、特にexpireしたCacheの削除は行われないことがわかります。 周辺の処理を確認しても特に削除する実装は存在しませんでした。
Scrapyのmiddlewareは自分で実装すことが可能なので新しくCacheを削除するmiddlewareを追加しました。
実装
下記のようにmiddlewareとして実装を行いました。
from scrapy.settings import Setting from scrapy.utils.misc import load_object import shutil import glob from pathlib import Path class CacheCleanMiddleware(object): def __init__(self, settings: Settings, crawler): self.crawler = crawler self.storage = load_object(settings['HTTPCACHE_STORAGE'])(settings) self.expiration_secs = settings.getint('HTTPCACHE_EXPIRATION_SECS') @classmethod def from_crawler(cls, crawler): o = cls(crawler.settings, crawler) return o def process_response(self, request, response, spider): rpath = self.storage._get_request_path(spider, request) cache_root_directory = Path(os.path.join(self.storage.cachedir, spider.name)) cache_directory = sorted(cache_root_directory.glob('*/*/'), key=lambda f: os.stat(f).st_mtime) for f in cache_directory: metapath = os.path.join(f, 'pickled_meta') if os.path.exists(metapath): mtime = os.stat(metapath).st_mtime if 0 < self.expiration_secs < time() - mtime: shutil.rmtree(Path(f).parent) cache_size = sum((os.path.getsize(f) for f in cache_root_directory.glob('**/*') if os.path.isfile(f))) if cache_size / 1024**2 >= 300: for i in range(cache_directory) / 3: metapath = os.path.join(f, 'pickled_meta') shutil.rmtree(Path(f).parent) return response
特に凝った実装は行っていませんがCacheの保存場所にあるCacheデータのmtmeを確認し、HTTPCACHE_EXPIRATION_SECSで指定された有効期間を過ぎていたらCacheを削除する仕組みになっています。また上限を300MBとし、300MB以上Cacheデータが増えた場合は古いCacheをある程度削除するような仕組みになっています。
まとめ
Scrapyのキャッシュを削除できるような処理を追加してみました。PC内で動かす際には特に問題ないのですが、Docker等リソースが限られている場合にScrapyを動かすとストレージが上限に達する場合があるので定期的にCacheを削除する必要が出てくるかなと思います。
Vaultを触ってみる
ZOZOテクノロジーズ #1 Advent Calendar 2020 21日目です。
今回はHashiCorpがリリースしているVaultについて触ってみました。
Vaultについて
Vaultはパスワードやアクセストークン等、機密情報を管理するソフトウェアです。 役割としてはgoogleのSecret MagegerやawsのSecrets Managerに近いです。
またVaultの機能として一時的にサーバーへアクセスできるTokenを発行するOne-Time Tokenの機能や各機密情報に関してユーザーの権限を設定することができるPolicyの機能があります。
Vaultのアーキテクチャについては下記の図になります。
 Architecture | Vault by HashiCorp
Architecture | Vault by HashiCorp
アーキテクチャについては下記の特徴があります。
Vault間で通信するデータは全てbarrierを通して暗号化され、通信される。
ストレージに保存される機密情報は暗号化され保存されるようになる。
Vaultの構築
今回はDocker上に構築を行います。 DockerのVersionに関しては下記になります。
- Docker:20.10.0
構築手順に関してはGetting Startedの部分を参考に構築します。
Vaultの起動の前にConfigファイルを設定します。Configファイルを設定しなくてもVaultを起動することができますが。デフォルトではUIが有効になっておらずAPIサーバのみ起動します。今回はUIを有効にして利用したいのでConfigファイルを有効にします。
VaultのConfigファイルの記述はHashiCorpが提供しているHCLになります。
今回は下記のような設定で動かします
storage "file" {
path = "./vault/data"
}
listener "tcp" {
address = "0.0.0.0:8201"
tls_disable = 1
}
api_addr = "http://0.0.0.0:8200"
ui = true
vaultのWebUIはデフォルトでは有効になっていないため設定で有効にする必要があります。 最終的に下記のDockerfileでまとまりました
FROM ubuntu:latest RUN apt update RUN apt install -y curl gnupg gnupg2 lsb-release RUN curl -fsSL https://apt.releases.hashicorp.com/gpg | apt-key add - && \ apt-add-repository "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main" && \ apt-get update && apt-get install vault COPY ./config.hcl ./config.hcl CMD vault server -dev -config=config.hcl
作成したDockerfileでコンテナを作成し、localhost:8001/uiにアクセスすると下記のUIが表示されます。
 今回はdevモードで起動しているのでコンテナを起動した際のConsoleに表示されているTokenを用いることでVaultにログインできます。
今回はdevモードで起動しているのでコンテナを起動した際のConsoleに表示されているTokenを用いることでVaultにログインできます。
 無事ログインできたことが確認できました。
無事ログインできたことが確認できました。
Secrets Enginesの設定
次にSecrets Enginesを用いてKey-Value Store(KVS)を作成してみます。Secrets Enginesの機能はPath形式でVaultにおいて機密情報をどこに保存するか設定できる機能になります。保存する場所はConsulやRabbitMQ等、様々なミドルウェアと連携できます。
今回はkv/hogeのPath名で、sample:sampleのKey-Value(KV)を保存しました。

policyの設定
次にpolicyの設定を行ってみます。
policyの設定はPoliciesタブで設定することができます。
policyの記述に関してもHCLで記述することができます。
許可されたユーザがkv/のPathを閲覧できるようにしたいので下記の設定を作成します。

付与した権限の詳細に関しては下記にまとまってます。
Authentication Methodsの設定
次にAuthentication Methodsを設定します。Authentication Methodsは名前の通り、認証方法を設定し、認証を利用するユーザーを管理することができます。認証方法はJwt認証やGithubの認証を使って認証する方法を設定できます。今回はUsername & Passwordで認証する方法を試してみます。
作成したユーザーは下記になります。sampleuserという名前で、先程作成したtest policyをアタッチしています。なのでこのユーザーはkv/のPathのみ閲覧することができます。追加でBOBというユーザを作成してます。こちらのユーザは特に何にもpolicyをアタッチしてないのでkv/のPathは閲覧できないように設定してます。
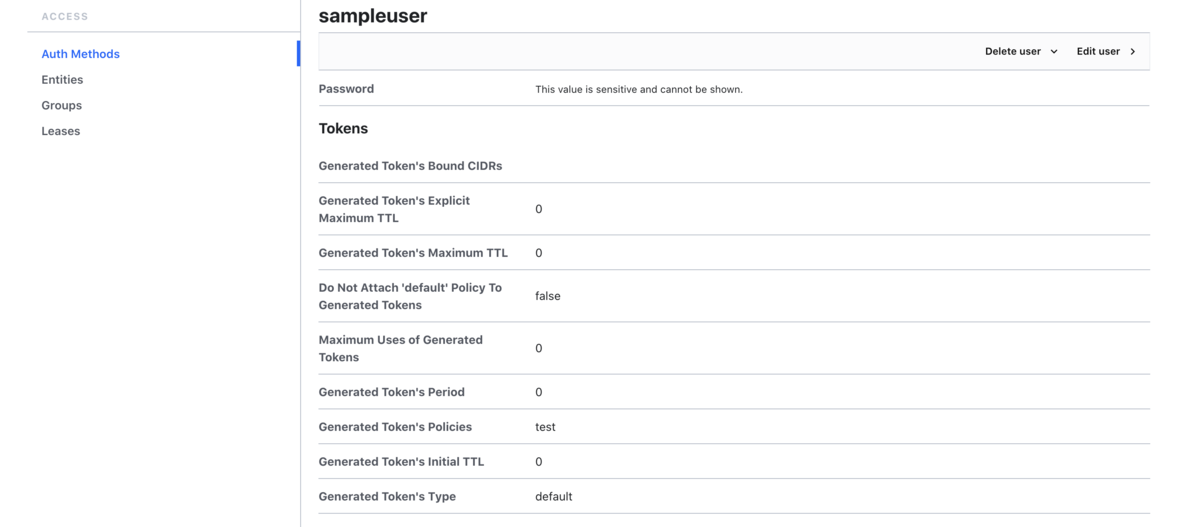
試しにログインして確認してみます。
sampleuserの画面
 BOBの画面
BOBの画面

sampleuserでkv/のPath以下に配置されているKVを閲覧することができました。また、別途作成したBOBのアカウントではkv/のPath以下は閲覧できないことがわかりました。
ちなみにBOBの画面に表示されているcubbyholeについてはユーザーアカウント毎にデフォルトで用意されているKVSになります。こちらで設定した値はユーザー毎にスコープされます。
https://www.vaultproject.io/docs/secrets/cubbyhole
まとめ
今回はVaultをdevモードで構築してみました。
awsやgcpやlocalで保存しているパスワードなどの情報をvaultで一括管理できるので便利だなと思いました。
しかしawsのsecrets magegerやgcpのsecret magegerと違い、Vaultを自前で運用する必要がでてくるので導入にはそれなりのコストが必要と思いました。
まだVaultの機能であるOne-Time Tokenの機能など、試していない機能もいくつか存在するので時間がある際に試してみようと思います。
mysqlのコンテナに初期データを流し込む
ゆるっと Advent Calendar 2020 13日目です。今回はmysqlのコンテナに初期データを流し込む方法について紹介します。
概要
開発環境を構築するためにDBのテーブルや初期データを配置したい場合があると思います。コンテナ起動後にデータを流し込む方法がありますがなるべく手間が無く構築できる方法がないか探しました。今回はmysqlについて探したところInitializing a fresh instanceの機能がありました。
MysqlのDockerhubのドキュメントに書かれているInitializing a fresh instanceの項目を引用すると
When a container is started for the first time, a new database with the specified name will be created and initialized with the provided configuration variables. Furthermore, it will execute files with extensions .sh, .sql and .sql.gz that are found in /docker-entrypoint-initdb.d. Files will be executed in alphabetical order. You can easily populate your mysql services by mounting a SQL dump into that directory and provide custom images with contributed data. SQL files will be imported by default to the database specified by the MYSQL_DATABASE variable.
つまり/docker-entrypoint-initdb.d ディレクトリに.sh, .sql, .sql.gzの拡張子のファイルを配置すると対象のファイルを読み込み、実行してくれます。実際に試してみます。
使用環境
実行例
下記のdocker-compose.ymlを用意します。
docker-compose.yml
version: '3' services: db: image: mysql:8.0 ports: - 3306:3306 environment: TZ: Asia/Tokyo MYSQL_ROOT_PASSWORD: root volumes: - ./mysql/:/docker-entrypoint-initdb.d/ command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
次に初期データを流し込むために下記のsqlファイルを用意します。
sample.sql
CREATE DATABASE IF NOT EXISTS sample; USE sample; CREATE TABLE IF NOT EXISTS sample_table ( `id` int(11) NOT NULL AUTO_INCREMENT, `sample` text, PRIMARY KEY (`id`) ); INSERT INTO sample_table (sample) VALUES ("sample1"); INSERT INTO sample_table (sample) VALUES ("sample2");
最終的に下記のディレクトリ構成でdocker-compose upを行いコンテナを生成、実行してみます。
./ ├── mysql │ └── sample.sql ├── docker-compose.yml
コンテナ起動後にdatabaseを確認すると無事テーブルと初期データが作成されていることがわかります。
mysql> select * from sample_table; +----+---------+ | id | sample | +----+---------+ | 1 | sample1 | | 2 | sample2 | +----+---------+ 2 rows in set (0.01 sec)
ではどのような仕組みで実行されているのかDockerfileの中身をみてみようと思います。
仕組み
対象のリポジトリは下記になります。
対象のDockerfileを確認するとentrypointがdocker-entrypoint.shに設定されています。docker-entrypoint.shの中身を見てみると
_main関数が初めに実行されることがわかります。関数内でdocker_temp_server_startが呼ばれてmysqlサーバが起動されているので以降の処理を追ってみます。docker_process_init_files関数で/docker-entrypoint-initdb.d/配下のファイルが渡されているので、この処理でsqlファイルの実行が行われていそうな気がします。
対象の関数内の中身をみると各拡張子ごとに処理を分けている部分があります。その中でdocker_process_sql関数が実行されmysqlコマンドが実行されているのでこの関数内でSQLが実行されていることがわかります。
まとめ
コンテナ作成時に初期データを流し込めるのは便利だと思いました。実装に関しても特に難しい処理は行われていないので他のDBにも流用できると思いました。
PythonでGCPの認証を行う
GCPの認証ってたまにどうやるんだっけ?って忘れてしまうので備忘録として残しておこうと思います。 今回はCloud Pub/Subを例に認証を行います。
今回使用する言語
- Python 3.7
予備知識
サービスアカウントとユーザーアカウントの認証の仕組みに関しては下記の記事が参考になります。
Cloud Pub/Subのlibraryの使い方に関しては下記になります。
サービスアカウントを用いて認証
環境変数を用いる
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
上記のようにサービスアカウントが含まれるパスを指定してあげるとclient libraryが使えるようになります こちらの方法だとCloud Pub/SubにPublishする際は下記のように扱うことができます。
from google.cloud import pubsub_v1 import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
ファイルパスを指定して認証
google.oauth2.service_account moduleを使って認証するやり方です。SERVICE_ACCOUNT_FILE_PATHの環境変数にファイルのパスを指定している感じです。
from google.cloud import pubsub_v1 from google.oauth2 import service_account import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") service_account_file_path = os.getenv("SERVICE_ACCOUNT_FILE_PATH", "") credentials = service_account.Credentials.from_service_account_file(service_account_file_path) publisher = pubsub_v1.PublisherClient(credentials=credentials) topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
データを直接読み込んで認証
同じように先ほどのgoogle.oauth2.service_account moduleを使います。
Credentialsクラスで定義されているfrom_service_account_infoメソッドを使うことでファイルパスを指定することなくサービスアカウントの情報を直接渡して認証できます。
特にコンテナなど、jsonファイルを中に置きたくない場合に有効なのかなと思います。SERVICE_ACCOUNT_FILEの環境変数にサービスアカウントの情報が入ってます。
from google.cloud import pubsub_v1 from google.oauth2 import service_account import json import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") service_account_file = os.getenv("SERVICE_ACCOUNT_FILE", "") credentials = service_account.Credentials.from_service_account_info(json.loads(service_account_file)) publisher = pubsub_v1.PublisherClient(credentials=credentials) topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
JWTを使って認証
google.auth.jwt.Credentialsを使って認証する方法です。
先ほどのgoogle.oauth2.service_account moduleの認証でもJWTを内部で扱っているのですが、アクセストークンの扱い方がそれぞれ違うみたいです。簡単にまとめると
| 使用ライブラリ | 認証方法 |
|---|---|
| google.oauth2.service_account module | JWTを用いてoauth2.0のアクセストークンを獲得して、GCPの認証はoauth2.0のアクセストークンをBearerトークンとして行う |
| google.auth.jwt.Credentials | JWTで生成したBearerトークンを使ってGCPの認証を行う |
のような違いがあるみたいです。
from google.cloud import pubsub_v1 from google.auth import jwt import json import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") service_account_file = os.getenv("GOOGLE_APPLICATION_CREDENTIALS", "") publisher_audience = "https://pubsub.googleapis.com/google.pubsub.v1.Publisher" credentials = jwt.Credentials.from_service_account_info(json.loads(service_account_file), audience=publisher_audience) publisher = pubsub_v1.PublisherClient(credentials=credentials) topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
ユーザーアカウントを用いて認証
環境変数を用いて認証
サービスアカウントを用いた方法と変わらないです。GOOGLE_APPLICATION_CREDENTIALSに使いたいユーザーアカウントのファイルパスを指定します。
ファイルパスを指定して認証
google.oauth2.credentials moduleを使って認証します。
from google.cloud import pubsub_v1 from google.oauth2 import credentials import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") user_account_path = os.getenv("GOOGLE_APPLICATION_CREDENTIALS", "") credentials = credentials.Credentials.from_authorized_user_file(user_account_path) publisher = pubsub_v1.PublisherClient(credentials=credentials) topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
データを直接読み込んで認証
こちらも同じようにgoogle.oauth2.credentials moduleを使います。
from google.cloud import pubsub_v1 from google.oauth2 import credentials import json import os project_id = os.getenv("PROJECT_ID", "") topic_id = os.getenv("TOPIC_ID", "") user_account_file = os.getenv("GOOGLE_APPLICATION_CREDENTIALS", "") credentials = credentials.Credentials.from_authorized_user_info(json.loads(user_account_file)) publisher = pubsub_v1.PublisherClient(credentials=credentials) topic_path = publisher.topic_path(project_id, topic_id) publisher.publish(topic_path, b"Hello World")
まとめ
google-authを眺めていると、まだ挙げていない認証方法もあるのかなと思います。最近は色々なクラウド環境を使う機会が増えてきたので、どのような認証方法が提供されているのか把握できてるとスムーズに開発が行えると思います。
とりあえずGCPの認証に関してはある程度理解できたので今後困ることはなさそうです。
Buildkitを使ってDockerfile以外からビルドする
ZOZOテクノロジーズ #4 Advent Calendar 2019 15日目の記事です。 今回はBuildkitを使ってDockerfile以外のsyntaxからImageをBuildしてみたいと思います。
Buildkitとは
BuildkitはMobyが開発しているOSSで、docker buildをより高速にセキュアにbuildできるツールらしいです。Docker18.09に正式統合され、DOCKER_BUILDKIT=1を指定すればBuildkitが有効になります。
実装の方針
Buildkitを使ってDockerfile以外からbuildするのですが、今回はyamlファイルからbuildできるようにしたいと思います。buildkitはbuildする際にLLBというDAG構造の中間言語に変換するのでdockerfile以外の記述方法に差し替えることが可能になっています。
実装方法としてはbuildkitを使うことで有効になるsyntaxフォーマットを利用することで実装できます。syntaxフォーマットを利用するとdocker buildする際に対応したdocker imageをDocker Hubからもってきて、grpc経由でbuildkitdとやり取りしてBuildするらしいです。なのでDocker Hubのアカウントが必要です。
では、これからDockerfileの代替としてSamplefileというものを作っていきます。
実装
コードの実装
Buildkitリポジトリに書かれているREADMEのExploring LLBの項目でBuildpacksやGockerfileを実装している人が紹介されていたので先人の人たちのコードを参考にしてかなり雑に実装したコードが下記のリポジトリになります。cmd/main.goがgrpc関連でbuild.goがYamlファイルをparseしてLLBに変換しているコードです。
buildしてDocker Hubにimageをpushする
下記のようにDocker HubにpushするためのDockerfileを作成します。
FROM golang:1.12.0 AS builder WORKDIR /build COPY . ./ RUN CGO_ENABLED=0 go build -o /sample ./cmd/ FROM scratch COPY --from=builder /sample /bin/sample ENTRYPOINT ["/bin/sample"]
次にbuildなのですが、気をつけることとしては、syntaxフォーマットで指定した名前と同じになるようにbuild tagをつけます。 私のDocker Hubのアカウント名はjon20なので下記のコマンドでbuildします。
docker build . -t jon20/samplefile
buildできたらDocker Hubにpushします。
docker push jon20/samplefile
確認
下記のようにSamplefile.yamlを適当なディレクトリに作成します。
#syntax=jon20/samplefile image: hello-world:latest
そしてdockerのbuildコマンドを実行します。
docker build -f Samplefile.yaml -t jon20/sample .
成功すれば下記のようにImageが作成されたことが確認できました。

まとめ
Dockerfile以外から無事buildすることができました。 正直な所、部分部分しか理解できておらず、説明不足な所が多いですがBuildkitに興味を持っていただければ嬉しいです。
Vue.jsでgoogle mapを利用する
ゆるっと Advent Calendar 2019 2日目です。
今回はVue.jsでgoogle mapを使う際によく使いそうなところを紹介できたらと思います。
下準備
今回使用するライブラリは以下になります。
yarn add vue2-google-maps
で追加できます。
index.jsを以下のように書き換えます。google mapのapiキーの取得に関しては割愛させていただきます。
import Vue from 'vue' import App from './App.vue' import * as VueGoogleMaps from 'vue2-google-maps' Vue.use(VueGoogleMaps, { load: { key: process.env.VUE_APP_GOOGLE_MAP_API, libraries: 'places', region: 'JP', language: 'ja' } }) Vue.config.productionTip = false new Vue({ render: h => h(App), }).$mount('#app')
google mapの表示
Quickstartに書いてるまんまのコードです。GmapMapコンポーネントを利用します。
<template>
<div>
<GmapMap
:center="{lat:10, lng:10}"
:zoom="7"
map-type-id="terrain"
style="width: 500px; height: 300px"
>
<GmapMarker
:key="index"
v-for="(m, index) in markers"
:position="m.position"
:clickable="true"
:draggable="true"
@click="center=m.position"
/>
</GmapMap>
</div>
</template>

google mapの設定
optionsプロパティにMapOptionsを渡せます。 例としてStreetViewの表示を消します。
<GmapMap
:center="{lat:10, lng:10}"
:zoom="7"
:options="{streetViewControl: false}"
map-type-id="terrain"
style="width: 500px; height: 300px"
>
<GmapMarker
:key="index"
v-for="(m, index) in markers"
:position="m.position"
:clickable="true"
:draggable="true"
@click="center=m.position"
/>
</GmapMap>
StreetViewのアイコンが消えているのが確認できました。

イベントの発火
全部試していませんが、公式に記載されているイベントトリガを使えます。 試しにマップのドラッグが終了した際にメソッドを実行してみます。
<template>
<div>
<GmapMap
:center="{lat:10, lng:10}"
:zoom="7"
:options="{streetViewControl: false}"
map-type-id="terrain"
style="width: 500px; height: 300px"
@dragend="onDragEnd"
>
<GmapMarker
:key="index"
v-for="(m, index) in markers"
:position="m.position"
:clickable="true"
:draggable="true"
@click="center=m.position"
/>
</GmapMap>
</div>
</template>
<script>
export default {
name: "HelloWorld",
methods: {
onDragEnd() {
console.log("hoge");
}
}
};
</script>
表示している領域の座標取得
getBoundsを使います。LatLngBoundsクラスが返されるのでgetCenterやgetSouthWestで中心座標や南西の座標が取得できます。
マーカの設置
すでにQuickstartでGmapMakerが定義されていますのでこれを流用してpositionを設定すればマーカーが設置できます。dataプロパティにmarkersを定義します。
export default { name: "HelloWorld", data() { return { markers: [{ position: { lat: 10, lng: 10 } }] }; }, methods: { onDragEnd() { console.log("hoge"); } } };
マーカーを設置できました。

マーカの上にWindowを表示
GmapInfoWindowコンポーネントを利用します。マーカーをクリックしたらWindowを表示します。 optionsプロパティでInfoWindowOptionsを設定します。今回はpixelOffsetだけ設定します。
<template>
<div>
<GmapMap
:center="{lat:10, lng:10}"
:zoom="7"
:options="{streetViewControl: false}"
map-type-id="terrain"
style="width: 500px; height: 300px"
@dragend="onDragEnd"
>
<GmapInfoWindow
:options="infoOptions"
:position="infoWindowPos"
:opened="infoWinOpen"
@closeclick="infoWinOpen=false"
>
hoge</GmapInfoWindow>
<GmapMarker
:key="index"
v-for="(m, index) in markers"
:position="m.position"
:clickable="true"
:draggable="true"
@click="toggleInfoWindow(m)"
/>
</GmapMap>
</div>
</template>
<script>
export default {
name: "HelloWorld",
data() {
return {
markers: [
{ position: { lat: 10, lng: 10 } },
{ position: { lat: 11, lng: 11 } }
],
infoOptions: {
pixelOffset: {
width: 0,
height: -35
}
},
infoWindowPos: null,
infoWinOpen: false
};
},
methods: {
onDragEnd() {
console.log("hoge");
},
toggleInfoWindow(marker) {
this.infoWindowPos = marker.position;
this.infoWinOpen = true;
}
}
};
</script>
hogeと書かれたWindowが表示されました。

まとめ
google mapを使用する際に使いそうな所を紹介しました。
結構細かく設定できるのでドキュメントを色々覗いてみるのも面白いと思います。